隐私计算(1)
本文以及系列文章根据陈凯、杨强老师撰写的《隐私计算》一书,系统的了解隐私计算相关技术和知识。
分为以下内容:
- 秘密分享
- 同态加密
- 不经意传输
- 混淆电路
- 差分隐私
- 可信执行环境
- 联邦学习
- 隐私计算平台
- 隐私计算案例解析
1. 隐私计算的定义和背景
根据隐私计算联盟和中国信息通信研究院云计算与大数据研究所与2021年7月发布的《隐私计算白皮书》中的定义,隐私计算是指在包志恒数据提供方不泄露原始数据的前提下,对数据进行分析计算的一系列技术,保障数据在流通和融合过程中“可用不可见”。
隐私计算结合密码学、统计学、计算机体系结构和人工智能等学科,其理论和应用的发展与云计算、大数据和人工智能的发展密不可分。目前,隐私计算主要应用于数据查询和分析与机器学习两大任务中。
- 数据查询和分析:该类应用以计算任务为核心,包含各类查询、求和、求平均和方差等简单的运算。在此过程中,如何定义数据拥有方的数据隐私并对其进行保护,是隐私计算的重要研究课题。
- 机器学习:在机器学习模型训练的过程中,隐私计算需要对来自数据拥有方的训练数据隐私进行保护;在使用模型对新的数据进行推理时,隐私计算需要对该推理数据隐私进行保护。
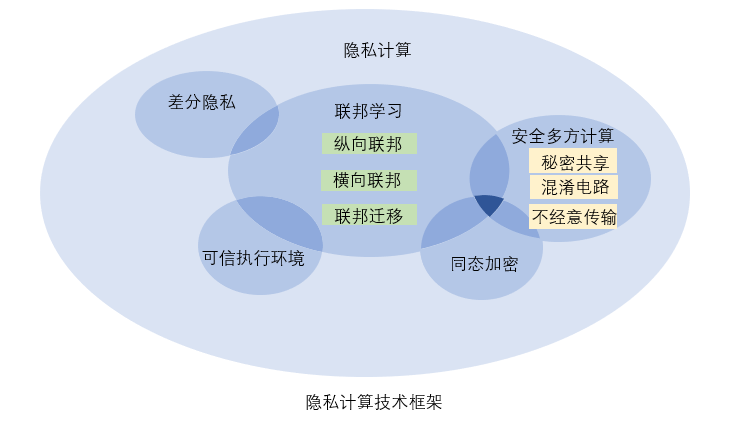
2.隐私计算分类:
按照历史发展过程、技术特点和隐私保护特征来看,隐私计算可以分为以基于密码学的安全协议为核心的隐私加密计算和外延含义更广的隐私保护计算。
- 隐私加密计算。是指使用密码学工具在安全协议层次构建隐私计算协议,从而实现多个数据拥有方在相互保护隐私的前提下,协同完成计算任务。此类技术的代表为安全多方计算。隐私加密技术拥有严格的安全证明保证隐私的密码学等级安全,但是由于密码学工具算法具有较高的复杂性,在实践中也非常低效。随着秘密共享、不经意传输、混淆电路和同态加密等密码学工具的不断发展,隐私加密技术仍然有广泛的适用场景和发展潜力。
- 隐私保护技术。为了在计算任务中对隐私进行更加细分的分析和控制,隐私计算的研究逐渐脱离出隐私加密计算的密码学范畴,在更加广泛的技术和应用场景下研究计算前对数据的安全获取和管理、计算过程中对数据隐私的保护,以及计算完成后对生成数据隐私的保护和相关权属与利益的分配,将这一系列新的隐私计算技术成为隐私保护计算。按照这些技术基于的研究发展轨迹、算法基础和应用特点,可以分为差分隐私、可信执行环境和联邦学习三种技术。
3.隐私计算的发展历程
现代隐私计算技术发展历程大致可以分为四个阶段:
第一阶段是安全多方计算理论和应用的发展。安全多方计算使用密码学工具构建了一个安全的计算模型,使得多个参与方可以使用自己的数据进行协作计算,同时保证自己的数据不泄露给其他参与方。其主要问题是性能与明文计算相比相差太大,最差情况可比明晚计算慢6个数量级,具体开销取决于计算与网络环境,其主要的性能瓶颈在于大量增加的通信开销。
第二阶段是差分隐私的理论和应用。差分隐私对计算过程和计算结果增加随机扰动,从而对个体数据进行混淆。不同于密码学理论论证破解难度来证明安全,差分隐私基于增加噪声带来的数据概率分布的混淆,在更加灵活的层面上评估自身的隐私保护能力。
第三阶段是以可信执行环境和全同态加密为代表的集中加密计算。与前两个阶段的思路不同的是,该阶段希望找到一个让数据安全地离开本地的方法。
- 其中一条路线是可信执行环境,其创造了一个隔离的运行环境,用户可以将自己的数据上传到可信执行环境中,而不必担心自己的数据被其他程序或者计算设备的管理者窃取。可信执行环境的实现依赖于厂商的特定硬件,例如Inter SGX、ARM TrustZone等,因此其安全性并不能够得到十分的保障,但其性能与明文直接计算相似,比同态加密更具实用性。
- 另一条技术路线是同态加密,同态加密使得我们可以在密文上直接计算得到有效的结果,不需要先解密再运算。同态加密需要付出额外的通信代价,这是将数据加密后进行传输产生的通信代价。另外,同态加密也带来了很大的额外计算代价,通常比明文计算慢6个数量级。
第四阶段是针对近似建模计算任务(例如机器学习建模和预测)设计的联邦学习。与以往的技术思路不同的是,联邦学习让各数据拥有方本地保存模型与数据,只在各方之间进行经过保护的参数信息的传递来完成训练过程。与传统的集中式机器学习相比,联邦学习的性能代价主要在于密文计算和传输中间结果产生的额外通信。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!