演化算法
遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世纪70年代提出,该算法是根据大自然中生物体进化规律而设计提出的。是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
1. 遗传算法概述
遗传算法由John H.Holland教授提出,为一种全局优化算法。它模拟自然进化与遗传理论,通过将优化问题进行转移,从而成功避免了一般优化算法中需要过多考虑的动力学信息问题,在原理上突破了常规的优化算法框架,算法结构较简单、处理信息能力较强,具有很好的鲁棒性。遗传算法最大的特点就是将优化问题中的参数转换成了编码的个体,从而不需要管理优化问题中的参数问题,只需要处理进行了编码的个体,而这些个体在遗传算法优化过程中所描述的就是生物界中“物竞天择,适者生存”的生存抉择概念。正是由于遗传算法具有上述等特点,现在被广泛用于各大领域,比如在一些优化问题复杂多样以及非线性等问题上,是21世纪以来智能算法中的比较突出的技术之一。
核心思想:
- 遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法
- 遗传算法起源于对生物系统所进行的计算机模拟研究。模仿自然界生物进化机制发展起来的随机全局搜索和优化方法,借鉴了达尔文的进化论和孟德尔的遗传学说。其本质是一种高效、并行、全局搜索的方法,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最佳解
- 遗传算法遵循自然界
适者生存、优胜劣汰的原则,是一类借鉴生物界自然选择和自然遗传机制的随机化搜索算法
达尔文进化论的主要观点是:物竞天择,适者生存。遗传算法的基本思想就是模仿自然进化过程,通过对群体中具有某种结构形式的个体进行遗传操作,从而生成新的群体,逐渐逼近最优解。在求解过程中设定一个固定规模的种群,种群中的每个个体都表示问题的一个可能解,个体适应环境的程度用适应度函数判断,适应度差的个体被淘汰,适应度好的个体得以继续繁衍,繁衍的过程中可能要经过选择、交叉、变异,形成新的族群,如此往复得到更多更好的解。
2. 遗传算法基本概念
- 基因(Gene):是生物界中表现生物体性状特征的一种遗传因子。在遗传算法中,基因的表示方法常常采用二进制(1 0)、整数或者某种字符来进行表达。
- 染色体(Chromosome):是生物界中的生物体表现遗传类特征的一种物质,也就是说它是基因存储的一种载体。
- 个体(Individual):个体所表现出来的是生物体带有特征的实体。在遗传算法进行遗传优化的过程中所优化的基本对象就是个体。
- 种群(Population):个体的集合称为种群。
- 群体规模(Population Size):群体规模表示的是整个种群中所有的个体数量总和。
- 适应度(Fitness):是个体优良的参考值。
- 编码(Coding):DNA中的遗传信息是按某种方式陈列在一个长链上。在遗传算法中,这实际上是一个映射过程,即先验参数到遗传参数的映射。
- 选择(Selection):描述的是“物竞天择,适者生存”的概念。在遗传算法中,参考个体适应值进行选择的过程。
- 复制(Reproduction):即DNA复制。在遗传算法中,对个体进行选择时,往往会根据群体规模来进行优良个体的复制。
- 交叉(Crossover):即杂交,是两个同源染色体在配对时,相互交换基因的过程。在遗传算法中,表示的是两个随机选择的个体进行信息互换的过程。
- 变异(Mutation):细胞在进行复制的时候,会出现很小的概率的差错,使得子染色体与母染色体不同,即发生变异。在遗传算法中,随机性的对个体中的信息进行改变的过程。
3. 算法流程
基本遗传算法(也称标准遗传算法或简单遗传算法,Simple Genetic Algorithm,简称SGA)是一种群体型操作,该操作以群体中的所有个体为对象,只使用基本遗传算子(Genetic Operator):选择算子(Selection Operator)、交叉算子(Crossover Operator)和变异算子(Mutation Operator),其遗传进化操作过程简单,容易理解,是其它一些遗传算法的基础,它不仅给各种遗传算法提供了一个基本框架,同时也具有一定的应用价值。选择、交叉和变异是遗传算法的3个主要操作算子,它们构成了遗传操作,使遗传算法具有了其它方法没有的特点。
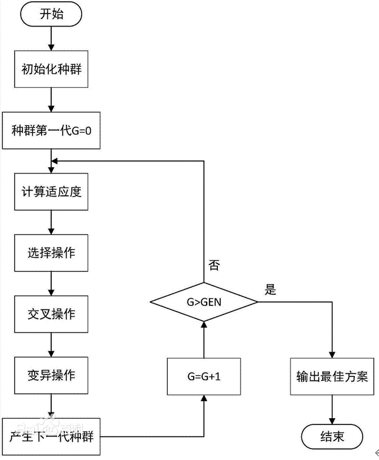
1) 编码和产生初始群体
根据优化函数的实际问题,选择好相应的编码方法,根据种群规模的需要,随机产生确定长度的n个染色体,作为初始种群。
$$
pop_i(t),i=1,2,3,…,n
$$
2)计算适应度值
假设适应度函数为$f(i)$,则对所有的个体计算其相对应的值为:
$$
f(i)=f(pop_i(t))
$$
3)终止判断
根据设定的终止条件判断是否达到收敛状态以选择下一步操作。
4)选择运算
选择适应度值大的个体进行交叉运算,则每个个体的选择概率为
$$
P_i=\frac{f(i)}{\sum_{i=1}^n f(i)},i=1,2,…,n
$$
以选择概率$P_i$作为新的概率分布,从当前种群中选择个体重组新的个体种群:
$$
newpop(t+1)={pop_j(t)|j=1,2,3,…,n}
$$
5)交叉运算
随机从种群中选择两个不同的个体,以概率$P_c$进行交换基因,得到新的两个个体,进行n/2次,得到一个新的种群$crosspop(t+1)$。
6)变异运算
从种群中随机选择个体,以变异概率$P_m$进行染色体变异,得到新的种群$mutpop(t+1)$,这个群体作为完成一次遗传操作的子种群,即$pop(t)=mutpop(t+1)$,此时传到第 2)步。
4. 实验实现GA算法
实验环境:windows 10、python 3.7、pycharm 2018
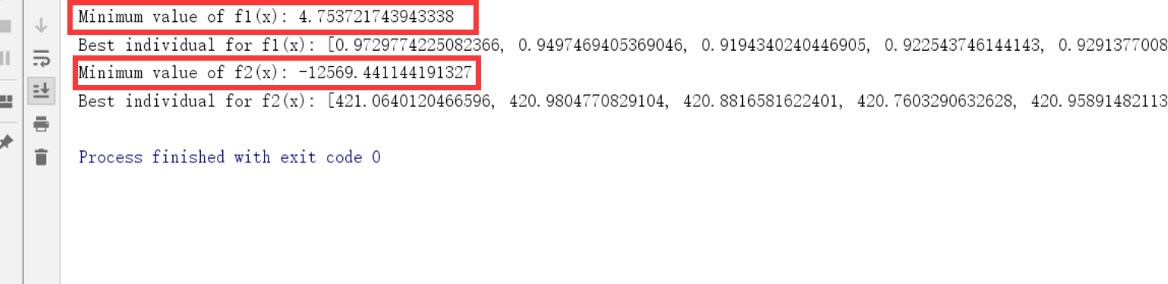
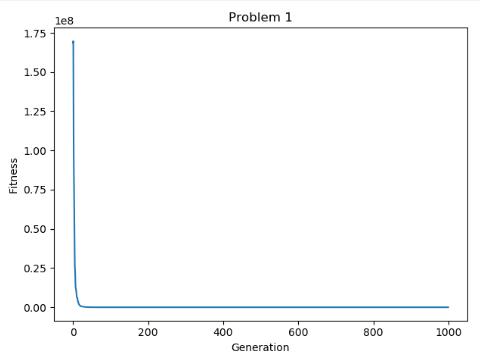
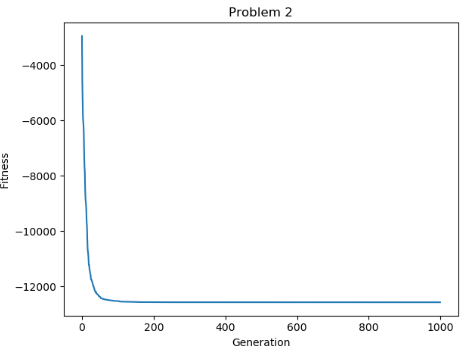
使用算法求解函数$f(x)=\sum_{i=1}^{29}[100(x_{i+1}-x_i^2)^2+(x_i-1)^2] ,-30 \le x_i \le30 \$ 和函数$f(x)=-\sum_{i=1}^{30}(x_isin(\sqrt{\lvert{x_i}\lvert})),-500\le x_i \le 500$的最小值
算法实现:
1 | |
实验结果:
与函数真实的全局最小值很接近:
5. 遗传算法的优缺点
遗传算法的优点
- 如果处理得当,可以在优化问题中得到全局最优解
- 比较容易实现并行化计算
- 遗传算法以结果为导向,最关注的两个点,一是编码与解码,一是适应度函数。它需要的背景知识少,也不需要太关注过程。所以应用范围非常广,可以解决非线性、不连续的问题,甚至有些无法清晰知道过程的问题,也可以解决
遗传算法的缺点
- 遗传算法非常依赖适应度函数,可以说适应度函数直接确定了结果的走向,而这个函数需要使用者自行提供,而且还没有标准,需根据实现问题总结出来
- 群体大小选择不当,或者选择压设置不对,都可能会过早收敛,错过全局最优解,只能达到局部最优解
- 因为遗传算法并不太关注过程,所以计算过程中的参数稍有不同可能会得到不同结果。这些参数包括群体大小、交换频率、突变频率等
- 当染色体过长(即基因数过多)时,需要重组的片段更多,导致群体规模非常大,使计算时间急剧增加
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!