ID3算法原理
ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
ID3算法
1. 算法概述
ID3算法是一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
决策树是对数据进行分类,以此达到预测的目的。该决策树方法先根据训练集数据形成决策树,如果该树不能对所有对象给出正确的分类,那么选择一些例外加入到训练集数据中,重复该过程一直到形成正确的决策集。决策树代表着决策集的树形结构。
2. 决策树
决策树(decision tree)是一类常见的机器学习方法。例如,我们要 对 “这是好瓜吗?”这样的问题进行决策时,通常会进行一系列的判断或“子决策”:我们先看“它是什么颜色?”,如果是 “青绿色”,则我 们再看“它的根蒂是什么形态?”,如果是“蜷缩 ”,我们再判断“它敲起来是什么声音?”,最后,我们得出最终决策:这是个好瓜。
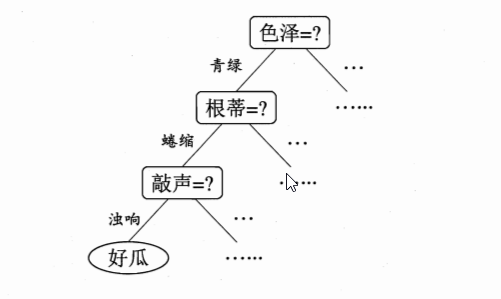
决策过程中提出的每个判定问题都是对某个属性的“测试 ”,每个测试的结果或是导出最终结论,或是导出进一步的判定问题,其考虑范围是在上次决策结果的限定范围之内。决策树学习的目的是为 了产生一棵泛化能力强,即处理未见示例能力强的决策树。
3. 信息熵和信息增益
==目标:选择最佳分类策略后,整体的信息熵变得最小。==
决策树的关键是如何选择最优划分属性,一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
经典的 “不纯度”的指标有三种,分别是信息增益(ID3 算法)、信息增益率(C4.5 算法)以及基尼指数(Cart 算法)
信息熵
信息熵是衡量样本集合纯度常用的一种指标,假设当前样本集合D中第$k$类样本所占的比例为$p_k(k=1,2,…,|y|)$,则D的信息熵定义为
$$
Entry(D)=-\sum_{k=1}^{|y|}p_klog_2\ p_k
$$
Ent(D)的值越小,则D的纯度越高;即信息熵越大,不确定性越大。
信息增益
假设离散属性$a$有$V$个可能的取值${a^1,a^2,…,a^V}$,则如果使用属性$a$来对样本集合D进行分类,会产生$V$个不同的分支,其中第$v$个分支结点包含了D中所有在属性$a$上取值为$a^v$的样本,记为$D^v$,可以根据信息熵的定义计算$D^v$的信息熵,再考虑不同的分支结点包含的样本数不同,给分支结点赋予权重$|D^v|/|D|$,于是可以计算使用属性$a$对样本集进行划分所获得的信息增益:
$$
Gain(D,a)=Ent(D)-\sum_{v=1}^V \frac{|D^v|}{|D|}Ent(D^v)
$$
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择。
4. ID3算法流程及实例
算法流程
核心思想:在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树。
具体方法:从根结点(root node)开始,对结点计算所有可能的特征信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择。最后得到一个决策树。
实例
数据集:
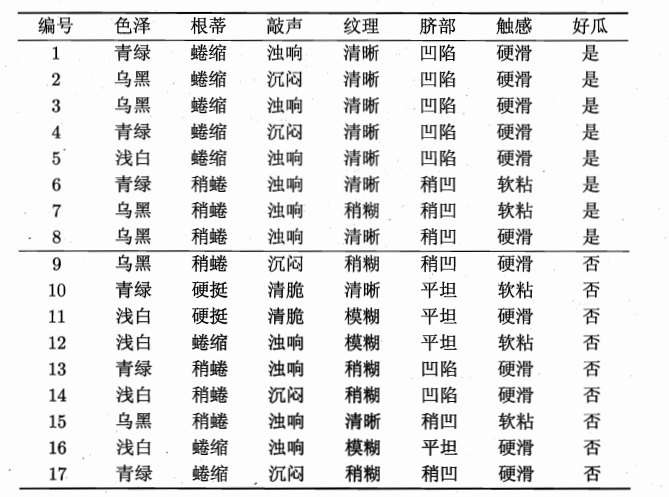
该数据集包含17个训练样例,用以学习一棵能预测没剖开的是不是好瓜的决策树。 在决策树学习开始时,根结点包含D中的所有样例,其中正例占$p_1=\frac{8}{17}$,反例占$p_2=\frac{9}{17}$,于是,根据定义可计算出根结点的信息熵为
$$
Ent(D)=-\sum_{k=1}^2p_k \ log_2\ p_k=-(\frac{8}{17}log_2\frac{8}{17}+\frac{9}{17}log_2\frac{9}{17})=0.998
$$
下面计算当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益。
以属性”色泽”为例,它有三个可能的取值{青绿,乌黑,浅白},如果使用该属性对D进行划分,则可以得到三个子集,记为$D^1$(色泽=青绿),$D^2$(色泽=乌黑),$D^3$(色泽=浅白)
子集$D^1$包含的样本共6个,编号为{1,4,6,10,13,17},其中正例占$p_1=\frac{3}{6}$,反例占$p_2=\frac{3}{6}$;子集$D^2$包含的样本共6个,编号为{2,3,7,8,9,15},其中正例占$p_1=\frac{4}{6}$,反例占$p_2=\frac{2}{6}$;子集$D^3$包含的样本共5个,编号为{5,11,12,14,16},其中正例占$p_1=\frac{1}{5}$,反例占$p_2=\frac{4}{5}$;计算出用“色泽”划分之后所获得的 3 个分支结点的信息熵为
$$
Ent(D^1)=-(\frac{3}{6}log_2\frac{3}{6}+\frac{3}{6}log_2\frac{3}{6})=1.000,
$$
$$
Ent(D^2)=-(\frac{4}{6}log_2\frac{4}{6}+\frac{2}{6}log_2\frac{2}{6})=0.918,
$$
$$
Ent(D^3)=-(\frac{1}{5}log_2\frac{1}{5}+\frac{4}{5}log_2\frac{4}{5})=0.722
$$
因此,计算出属性色泽的信息增益为:
$$
Gain(D,色泽)=Ent(D)-\sum_{v=1}^3\frac{|D^v|}{|D|}Ent(D^v)
$$
$$
=0.998- (\frac{6}{17}×1.000+\frac{6}{17}×0.918+\frac{5}{17}×0.722)=0.109
$$
类似的,计算其他属性的信息增益:
$$ Gain(D,根蒂)= 0.143; Gain(D , 敲声)= 0.141; $$$$ \
Gain(D ,纹理)= 0.381; Gain(D , 脐部)= 0.289;$$ $$ \
Gain(D ,触感)= 0.006.$$
属性 “纹理”的信息增益最大,于是它被选为划分属性。
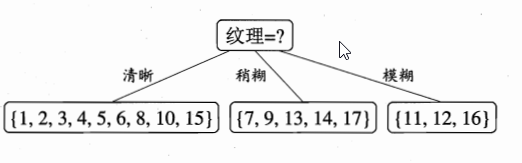
然后,决策树学习算法将对每个分支结点做进一步划分。
5. ID3算法缺点
- ID3没有剪枝策略,容易过拟合
- 信息增益准则对可取值数目较多的特征有所偏好。因为相同条件下,取值比较多的特征的信息增益大于取值较少的特征
- 只能用于处理离散分布的特征,没有考虑到特征连续值的情况,即如人的身高、体重都是连续值,无法在ID3算法中应用,即ID3算法更适合做分类
- 没有考虑缺失值
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!